
Agent Memory Is Not RAG: a Practical Map for Building Long-Horizon AI Agents
Why “short vs long-term” could be not enough—and how to think in forms, functions, and lifecycles when you design memory.

If you’re building AI agents, you’ve probably added “memory” at some point—RAG, long context, a vector store, maybe a summary buffer—and still watched the agent drift, repeat mistakes, or forget the one thing that mattered.
That’s because we often treat memory as a single feature. In practice, memory is a system: different representations, different purposes, and a lifecycle that needs rules (not just storage).
In this post I’ll give you a practical map to design agent memory that actually works: what memory is made of (forms), what it’s for (functions), and how it evolves over time (dynamics)—the pieces that determine whether memory makes your agent reliable or just noisier.
If you like pragmatic deep-dives on LLMs, agents, and real-world ML engineering, subscribe to this Substack so you don’t miss the next one.
Memory in the Age of AI Agents (and why “long-term vs short-term” isn’t enough anymore)
LLM agents don’t fail only because they “forget” something. They fail because we keep treating memory as a single feature, when in practice it’s an entire system with different representations, purposes, and update rules.
The paper “Memory in the Age of AI Agents: A Survey — Forms, Functions and Dynamics” (Hu et al., arXiv:2512.13564, Dec 2025) is the best attempt I’ve seen to bring conceptual order to the chaos. It’s a survey, but it reads like an architectural map: it separates what memory is made of, what it’s for, and how it evolves over time—and it explains why the old taxonomy (“short vs long term”) is too coarse for modern agent stacks.
Below is the version I’d want if I had 8 minutes and I’m about to design an agent that must survive beyond a single chat window.
First: “Agent memory” is not just RAG, and not just long context
A lot of confusion comes from mixing four things:
RAG: fetch external knowledge at query time.
Context engineering: prompt/format/tooling tricks to make the model behave.
LLM memory (in the “model internals” sense): attention/KV cache tricks, long-context architectures, compression.
Agent memory: a persistent, self-evolving cognitive state that accumulates facts and experience across interactions.
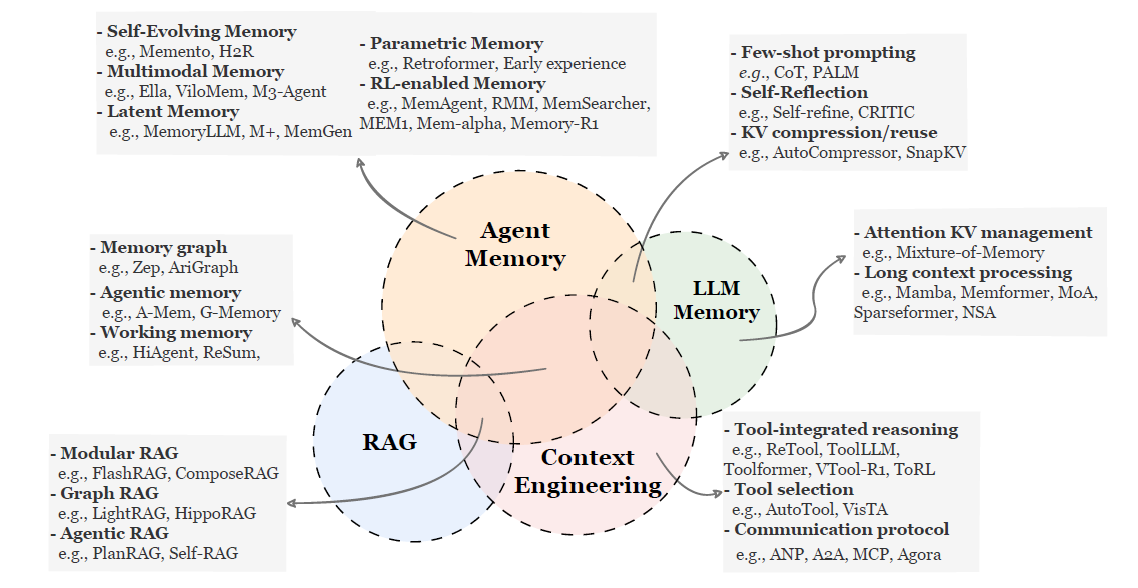
This distinction matters because each bucket implies different evaluation criteria. RAG is about retrieval quality; long-context is about sequence handling; agent memory is about adaptation over time.
Instead of forcing everything into “short vs long term”, the survey proposes three orthogonal lenses:
Forms (how memory is represented)
Functions (why memory exists / what role it plays)
Dynamics (how it gets created, updated, and used)
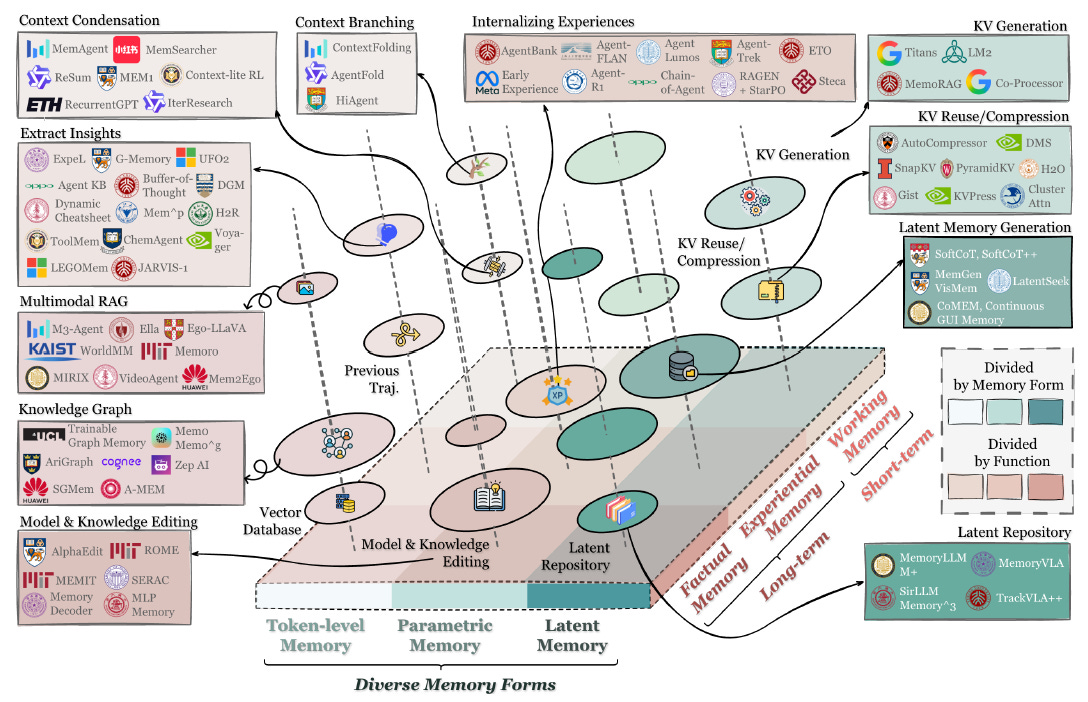
What “memory” is made of
The survey frames modern agent memory as multiple representational choices. The abstract highlights contextual, external, parametric, and latent memory—each with different trade-offs.
Contextual memory (in-context)
This is the simplest: keep relevant information in the prompt/context window (possibly compressed/summarized).
Pros: trivial to implement, transparent.
Cons: expensive, brittle, and capped by context limits; also easy to “drift” as the conversation grows.
External memory (stores outside the model)
Vector DBs, key-value stores, knowledge graphs, episodic logs—anything retrievable and persistent.
Pros: scalable, editable, inspectable; can support provenance and access control.
Cons: retrieval is a whole subsystem; quality depends on chunking, embeddings, ranking, and query formulation.
Parametric memory (in the model weights or add-on modules)
This includes weight updates, model editing, adapters/LoRAs, or auxiliary modules that “store” knowledge in parameters.
Pros: fast at inference; can internalize patterns.
Cons: hard to debug; risk of interference; updating is non-trivial and can be costly.
Latent memory (inside hidden states / KV / internal representations)
Instead of storing human-readable text, memory lives as latent embeddings, cached states, or learned compressed representations.
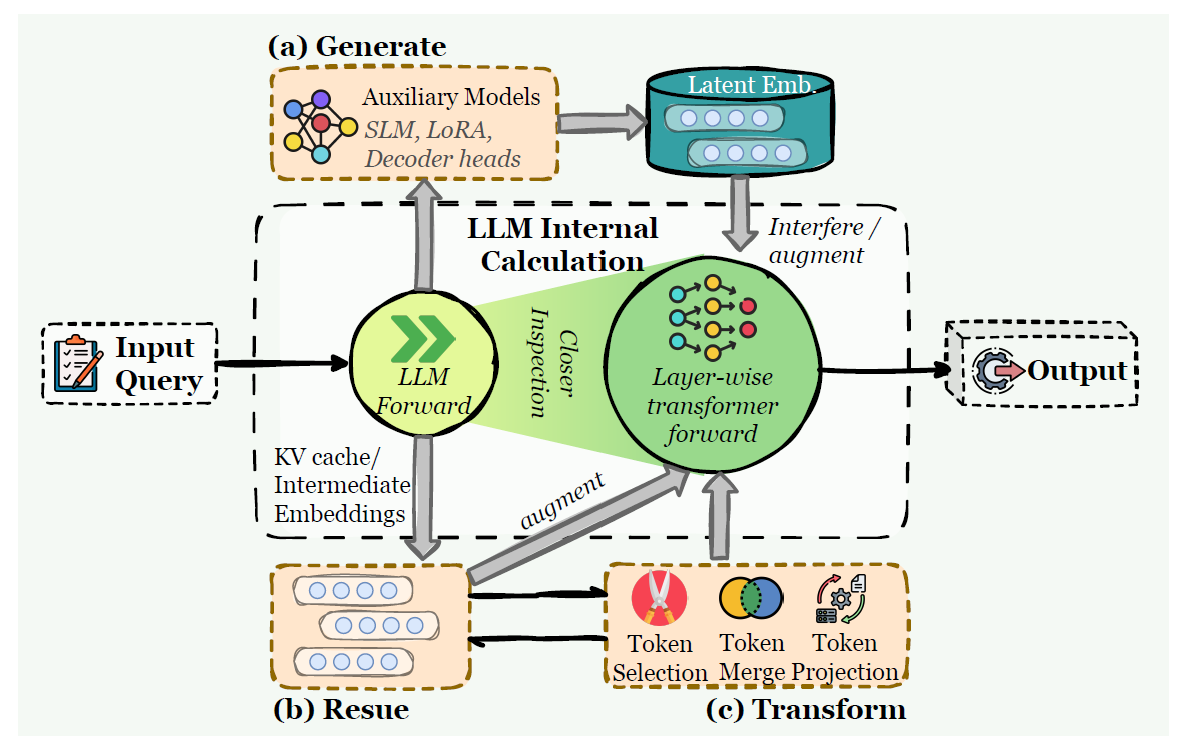
When you should care: when you want memory-like behavior with lower latency and without dumping everything into a text store—but you accept that interpretability drops.
What memory is for (three pillars)
This is the part most teams skip. They build “memory” as storage, then wonder why it doesn’t improve agent reliability. The survey proposes three primary functions.
Factual memory — “What does the agent know?”
Stable declarative knowledge: user preferences, constraints, environment state, long-lived facts that keep behavior consistent.
Experiential memory — “How does the agent improve?”
Procedural knowledge distilled from trajectories: what worked, what failed, strategies, skills, heuristics. This is the agent getting better over time—without you hand-authoring rules.
Working memory — “What is the agent thinking about now?”
A controlled scratchpad to manage context during the task: subgoals, intermediate results, plan state, tool outputs, “current hypothesis”.
A useful mental model:
Factual = identity and continuity
Experiential = learning and skill
Working = cognition-in-motion
If your agent is flaky, ask which function is missing. Most “memory” implementations only cover factual memory (sometimes poorly) and ignore experiential + working memory entirely.
Memory isn’t a database, it’s a lifecycle
The paper formalizes agent memory as an evolving state with three core operators:
Memory formation: turn raw interaction artifacts into candidates worth keeping
Memory evolution: consolidate, resolve conflicts, forget, restructure
Memory retrieval: decide what to pull, when, and how to integrate it into reasoning
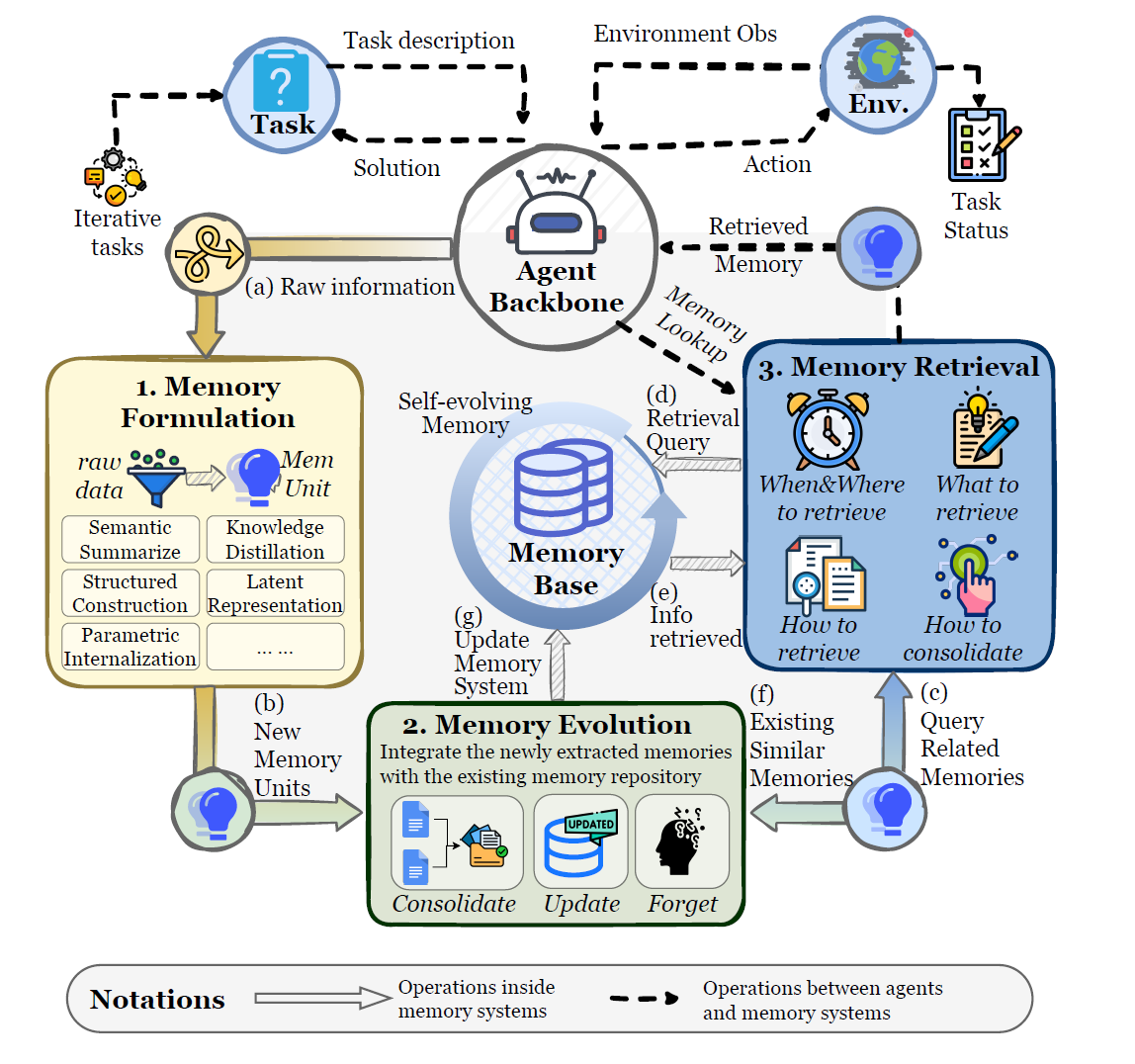
This is where agent memory becomes engineering, not vibes. You need policies:
What gets stored (and at what granularity)?
How do you prevent redundant or contradictory entries?
When do you summarize vs retain raw traces?
How do you retrieve without polluting the context?
How do you measure whether memory helped?
A killer insight here: temporal labels (“short-term/long-term”) often emerge from usage patterns, not from separate components. A single memory substrate can behave short-term or long-term depending on how you form/evolve/retrieve.
What I’d take from this paper if I’m building an agent this week
Here’s a practical checklist inspired by the taxonomy:
1) Choose the function before the storage.
Are you trying to preserve facts, learn strategies, or manage active context? Pick one primary target first.
2) Don’t ship memory without evolution rules.
If you only “append”, your agent will degrade: contradictions, prompt bloat, retrieval noise. You need consolidation + forgetting.
3) Evaluate memory on long-horizon tasks.
A memory system that helps on turn 3 but hurts on turn 30 is not “working”.
4) Treat memory as an attack surface.
Poisoning, prompt injection via memory items, privacy leakage, provenance: once memory persists, mistakes persist too.
A forward-looking angle the paper gets right: RL is coming for memory
One of the most interesting parts is the trajectory toward learning memory policies (what to store, how to update, what to retrieve) instead of hand-designing them.
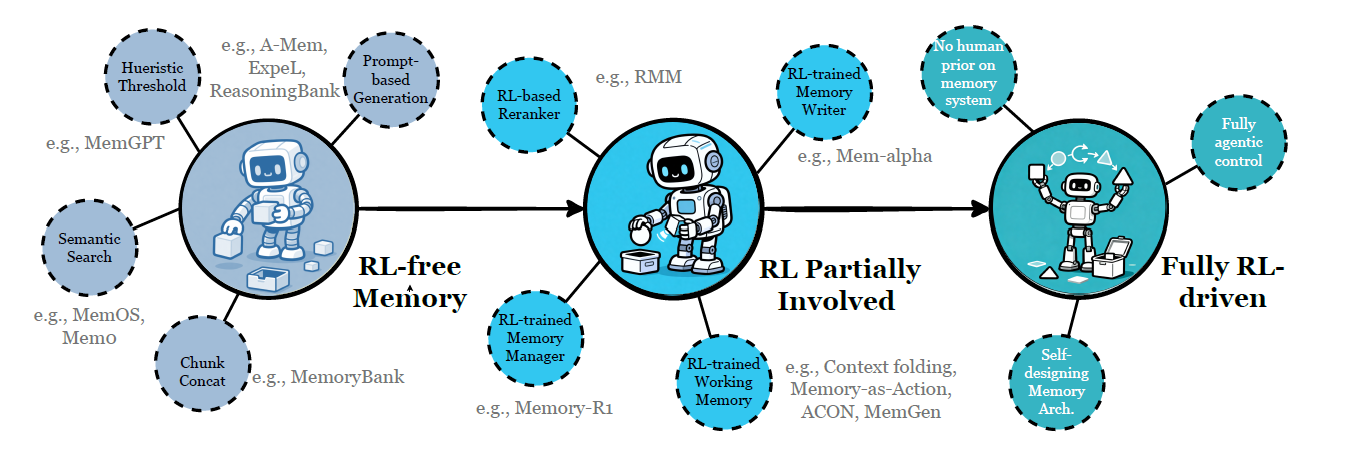
Even if you’re not doing RL today, this matters: the “memory manager” may become a trainable component, not a pile of heuristics.
If you don’t want to miss the next deep-dives (agents, memory, distillation, infra), subscribe. No spam—just the few things worth your time.
This distinction matters so much. I kept bolting RAG onto my agent's memory system and wondering why it felt brittle.
The breakthrough for me was treating memory as architecture, not storage. My agent Wiz runs on a three-tier system: static instructions (CLAUDE.md), working context (per-session), and persistent auto-memory that rolls over. Each tier has different update rules and trust levels.
The 'integrated system rather than isolated storage' framing matches exactly what I learned the hard way. Memory isn't a feature you add - it's the backbone everything else hangs on.
Wrote about my practical memory architecture: https://thoughts.jock.pl/p/how-i-structure-claude-md-after-1000-sessions
What's your take on when episodic memory becomes more valuable than semantic memory for agents?